关系型数据库总览
目录
如何设计一个关系型数据库?

1.文件系统,将数据持久化到存储设备中。
2.程序实例, 对存储进行逻辑上的管理:
a.缓存机制:优化执行效率
b.日志管理:记录操作
c.容灾机制:灾难恢复
d.索引管理: 优化数据查询效率
e.锁管理:支持并发操作
索引管理
为什么要使用索引?
1.在行数据非常多的情况下,避免全表扫描。
2.类似字典,索引就是将一些关键信息组织起来,
根据索引可以快速查找到对应的信息。
什么样的信息能成为索引
主键、唯一键以及普通键等。
索引的数据结构
1.二叉查找树进行二分查找。
2.B树结构进行查找。
3.B+树结构进行查找。
4.建立Hash结构进行查找。
优化索引
二叉查找树
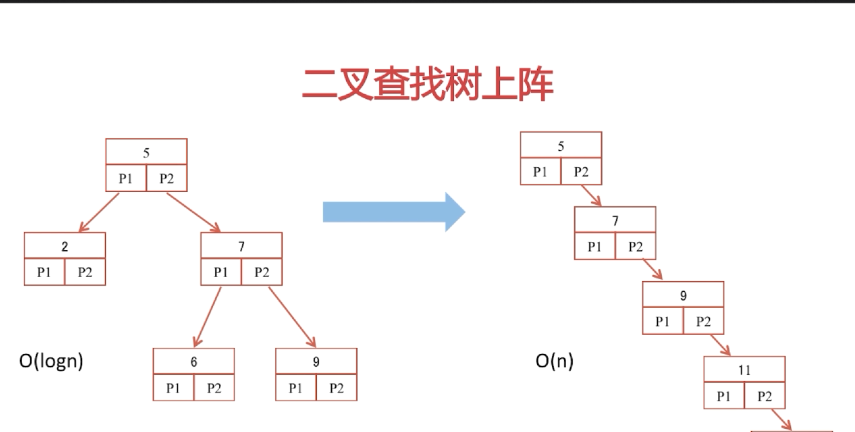
二叉查找树:
1.每个根节点,只有两个孩子节点。
2.左孩子节点一定小于根节点,右孩子节点一定大于根节点。
3.查找时,类似二分,时间复杂度为O(logn)。
缺点:
极限情况下,插入节点时一直比根节点大,就会如上图右半部份变为线性机构,
时间复杂度退化为O(n)。
B树
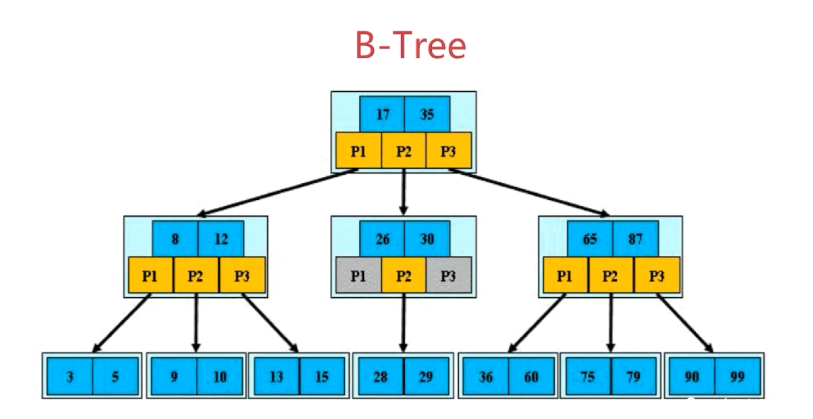
简单概念:
1.如果每个节点最多有m个孩子,那么就是m阶B树,如上图就是一个3阶B树。
2.每个存储块中主要包含了关键字和指向孩子的指针。
3.最多能有几个孩子取决于模块的存储容量和数据库的配置。
4.B树又叫平衡多路查找树。
5.叶子节点:没有孩子节点的节点叫作叶子节点。
非叶子节点:跟叶子节点相反,有孩子节点的节点。
定义:
1.根节点至少包括两个孩子:
上图第一层就是根节点,它有三个孩子(第二层节点树)。
2.树中每个节点最多包含m个孩子(m>=2):
上图m=3,那么最多有3个孩子.
3.除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子(向上取整,也就是至少有2个孩子)。
根节点是第一层,叶节点是第二层,这两层不用必须满第3条规则。上图,第二层中间叶节点,只有一个孩子是允许的。
4.所有叶子节点都位于同一层。
上图中,第3层就是叶子节点。
5.假设每个非终端节点中包含n个关键字信息,其中:
a.Ki(i=1...n)为关键字,且关键字按顺序升序排序K(i - 1)< Ki
解释:
上图中,每个节点里的关键字是从左到右升序,例如:第2层第一个节点的8和12
b.关键字的个数n必须满足:[ceil(m / 2) - 1 <= n <= m - 1]
解释:
上图中,任意节点的关键字数量比它的孩子数上限少一个。由于指针会指向孩子节点,
也可以理解为,关键字数量比指针数量少一个。
例如:第2层第一个节点, 关键字有2个(8和12),指针数量3个(p1,p2,p3)。
C.非叶子节点的指针:P[1], P[2], ..., P[M];其中P[1]指向关键字小于K[1]的子树,P[M]
指向关键字大于K[M - 1]的子树,其它P[i]指向关键字属于(K[i - 1], k[i])的子树。
解释:
上图中,第2层第一个节点
节点最左边的关键字,均大于子树的关键字。8 大于 3 和 5 。
节点最右边的关键字,均小于子树的关键字。12 小于 13 和 15 。
中间的指针p2指向的子树的关键字9 和 10 均处于 8 和 12 之间。