项目线程驱动模型
目录
一:核心思想
1.线程池执行任务和线程分离,换句话说就是执行任务的线程不绑定,
哪个线程有空闲谁就执行。
2.采用master-worker模式。
二:主要流程
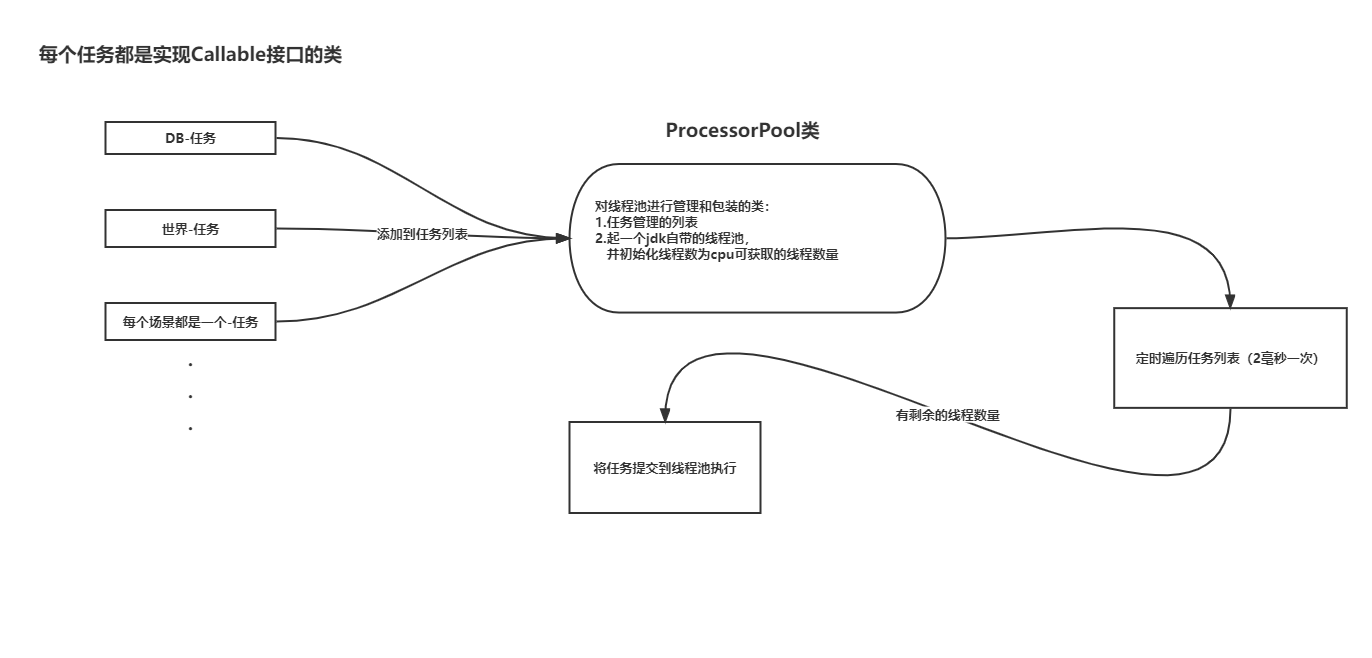
1.项目的DB线程、世界线程、场景线程并不是传统意义上真正起一个线程去做专们的事情,
而是实现Callable接口的任务,线程池执行任务和线程分离,换句话说就是执行任务的线程不绑定,
哪个线程有空闲谁就执行。
2.起服时将DB任务和世界任务添加到ProcessorPool类的任务管理列表(就是一个list),
场景激活时场景任务添加到ProcessorPool类的任务管理列表。
3.ProcessorPool类,核心参数:
a.自己实现了一层对线程池进行管理和包装的类
b.拥有一个任务列表(Callable接口任务)
c.起了一个jdk自带的线程池并初始化线程数为cpu可获取的数量
d.任务执行结果列表
4.ProcessorPool类定时遍历任务列表(2毫秒一次)
5.将任务提交到线程池执行:
a.Future future = executorService.submit(processor);
这里的processor就是实现的Callable接口的类
b.将返回的结果future添加到ProcessorPool结果列表里
6.遍历结果列表(future列表),进行处理
7.由于任务列表一直没有移除,所以ProcessorPool会一直重复步骤4-6
8.题外话:
项目创建线程池采用的是, Executors.newFixedThreadPool(threadCount)。你可能听过阿里不建议采用此方式,
因为newFixedThreadPool允许的请求队列长度为Integet.MAX_VALUE,可能会堆积大量的请求从而导致OOM。
但是其实你从上面图就可以知道,项目中线程池的任务的数量一定是固定的,主要也就是世界任务、DB任务
场景任务(有最大限制的:假设5000)以及几个其它辅助的任务等,远远不可能超出Integet.MAX_VALUE。
所以可以直接用Executors.newFixedThreadPool(threadCount)来创建线程池。
三:任务执行
/**
* 线程处理器,是core这个层面的线程包装
* 也是core这个层面的最底层执行单位,可以
* 认为一个processor就是一个线程Callable
*/
public class Processor implements Callable<AbstractService>
{
@Override
public AbstractService call() throws Exception
{
try
{
if (!isActive)
{
service.inactive();
service.active();
isActive = true;
}
service.tick0(interval);
}
catch (Exception e)
{
e.printStackTrace();
CoreLog.CORE_COMMON.error("processor call exception message:{}", e.getMessage());
CoreLog.CORE_COMMON.error("processor call exception:{}", ExceptionUtils.exceptionToString(e));
}
catch (Error error)
{
error.printStackTrace();
CoreLog.CORE_COMMON.error("processor call error:{}", ExceptionUtils.exceptionToString(error));
}
finally
{
statusEnum = ProcessorStatusEnum.IDLE;
return service;
}
}
}
总结:
1.可以看出,任务执行就是在不停的驱动tick,有点类似客户端定时刷新帧。
2.我们平时业务的逻辑就是在tick逻辑下做逻辑,这样做的好处,业务人员开发功能时
可以认为自己是在单线程下做逻辑,屏蔽了很多并发问题。
四:任务移除
例如:某个场景没人并且当前场景不是常驻场景,那么我们需要将场景进行回收。
CoreGlobals.getInstance().getProcessorPool().removeService(scene);
场景的回收,其实就是将当前场景任务从ProcessorPool类的任务管理列表移除即可。