G1学习
目录
G1简介
适用于大内存的机器,可预测的停顿(尽可能,无法保证), 低延时,高吞吐。
目标是长期替代CMS垃圾收集器。
G1的内存布局

传统的GC收集器将连续的内存空间划分为新生代、老年代和永久代(JDK 8去除了永久代,引入了元空间Metaspace),这种划分的特点是各代的存储地址(逻辑地址)是连续的。

而G1的各代存储地址是不连续的,每一代都使用了n个不连续的大小相同的Region,每个Region占有一块连续的虚拟内存地址。
这里的Humongous大对象,默认是大于等于region的一半的对象被分配在Humongous区域。大对象属于old区域。
G1内部细节
会估计每个Region中的垃圾比例,优先回收垃圾多的Region,这就是为什么叫Garbage First 原因。
1.Collection Set(CS)
GC时需要回收的Region区域的集合叫Collection set,CSet集合里的Region可以是任意年代的, 主要作用是避免堆全扫描。
无需回收整个堆,而是选择一个Collection Set(CS)。
cset对JVM大小的影响小于1%。
2.Remebered Set (RS) 和 Card Table
1.Remebered Set (RS)
用于解决对象在region与region之间的跨代引用问题。
逻辑上说每个Region都有一个RSet,RSet记录了其他Region中的对象引用本Region中对象的关系,属于points-into结构(谁引用了我的对象)。
Rset占总内存小于%5。
在Eden regions中分配对象,当所有的Eden regions填满的时候,触发Young GC。同时更新对存活对象的引用。
G1 也属于分代收集器,G1 是从逻辑上划分 Young Generation 和 Old Generation,没有从物理存储空间上将不同代隔离开 ( Region 可以在 Old 和 Young Generation 之间切换)。
G1是分代收集的好处就是将 long-live object 和 short-live object 分开收集,从而不用每次 GC 都扫描整个 Heap,降低 GC 时间。
那么 YGC 的时候,放入 CSet (一次 GC 中参与收集的所有 Region 组成的集合叫做 CSet)的只有 Young Generation Region,所有 Old Generation Region 都不会参与 YGC。
于是就需要有机制去保证年轻代上的 Object 在被老年代上某个 Object 引用时,这个年轻代上的 Object 不能在 YGC 的时候被 GC 掉。所以需要有个地方能记录每个 Object 都被哪些引用指向,这些引用来自哪个 Region。
另一方面,YGC 和 OGC 在执行完后都会有 live object 被搬迁到新的 Free Region 上,那么指向这些 live object 的引用就会发生变化,需要更新引用让其重新指向这个 live object 的新地址。所以也需要上述这个记录每个 Object 被哪些引用指向的机制,从而在 GC 后去更新引用。G1 中每个 Region 都会维护一个 Remember Sets,也叫 RSet,用于记录当前 Region 之外,有哪些 Region 有指向当前 Region 的引用。
2.Card Table
Card Table则是一种points-out(我引用了谁的对象)的结构, 每个Card 覆盖一定范围的Heap(一般为512Bytes)。G1的RSet是在Card Table的基础上实现的:每个Region会记录下别的Region有指向自己的指针,并标记这些指针分别在哪些Card的范围内。 这个RSet其实是一个Hash Table,Key是别的Region的起始地址,Value是一个集合,里面的元素是Card Table的Index。
3.图解
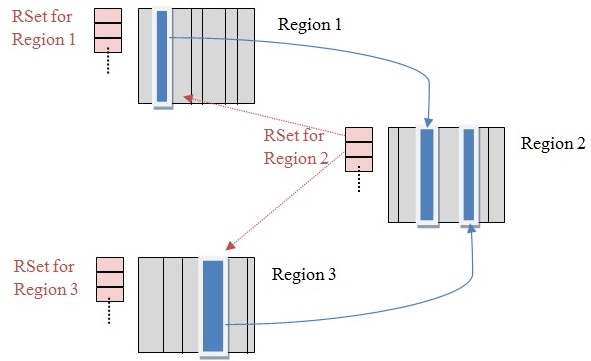
上图中有三个Region, 每个region被分成多个Card(灰色区域),在不同Region中的Card会相互引用,Region1中的Card中的对象引用了Region2中的Card中的对象,Region3中的Card中的对象也引用了Region2中的
Card中的对象,蓝色实线表示的就是points-out(我引用了谁)的关系, 同时我们看到Card被置脏。
而粉色区域则代表RSet, 每个Region有对应的一个RSet, RSet属于points-into结构(谁引用了我的对象),图中Resion2的RSet被Resion1和Resion2的Rset引用着,粉色箭头。
3.Rest的维护
维系RSet中的引用关系靠post-write barrier和Concurrent refinement threads来维护。
post-write barrier记录了跨Region的引用更新,更新日志缓冲区则记录了那些包含更新引用的Cards。一旦缓冲区满了,Post-write barrier就停止服务了,会由Concurrent refinement threads处理这些缓冲区日志。
1.Write Barrier
Write Barrier 在垃圾收集器中是由编译器在每个存储操作之前生成的一段代码,保证代与代之间的关系可以被维护起来。
就是说jvm每当执行赋值操作的时候,
例如:
object.field = <reference>(putfield)
jvm会注入一小段代码,用于记录指针变化
//todo todo
4.RSet究竟是怎么辅助GC的呢
在做YGC的时候,只需要选定young generation region的RSet作为根集,这些RSet记录了old->young的跨代引用,避免了扫描整个old generation。
而mixed gc的时候,old generation中记录了old->old的RSet,young->old的引用由扫描全部young generation region得到,这样也不用扫描全部old generation region。所以RSet的引入大大减少了GC的工作量。
5.STAB
snapshot-at-the-beginning (SATB), 俗称”快照”,是G1垃圾收集器里用于并发标记的一种算法。
SATB标记算法也有非常小的暂停时间。
6.Pause Prediction Model停顿预测模型
G1回收过程
1.G1 GC两种模式
Fully young GC
Mixed GC
G1提供了两种GC模式,Young GC和Mixed GC,两种都是完全Stop The World的。 * Young GC:选定所有年轻代里的Region。通过控制年轻代的region个数,即年轻代内存大小,来控制young GC的时间开销。 * Mixed GC:选定所有年轻代里的Region,外加根据global concurrent marking统计得出收集收益高的若干老年代Region。在用户指定的开销目标范围内尽可能选择收益高的老年代Region。
由上面的描述可知,Mixed GC不是full GC,它只能回收部分老年代的Region,如果mixed GC实在无法跟上程序分配内存的速度,导致老年代填满无法继续进行Mixed GC,就会使用serial old GC(full GC)来收集整个GC heap。所以我们可以知道,G1是不提供full GC的。