jvm性能调优基础学习
目录
为什么学习jvm?
java把内存管理交给了jvm,虽然给我们带来了很大的遍历,但任何事情都有两面性。
如果你不了解jvm干了什么,当发生内存泄漏怎么办?
简单认识jvm运行时数据区
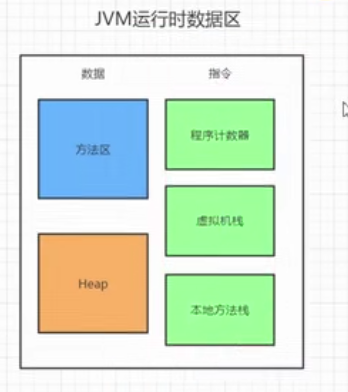
一般我们写代码,就是写数据、指令、控制。
数据:类里的成员变量
指令:int a = 10
控制: return
如图为1.7的运行时数据图:
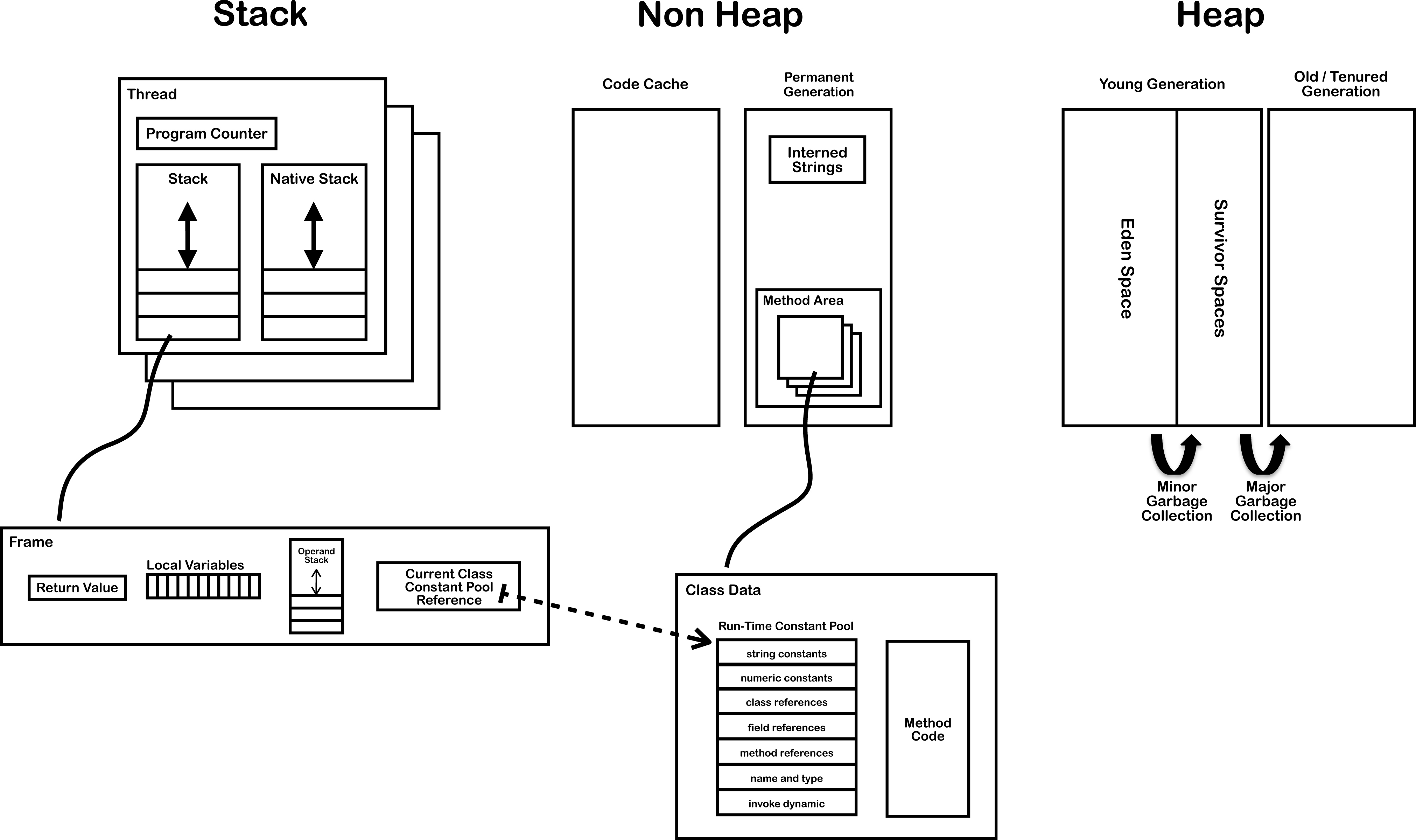
1.我们可以看到虚拟机栈,每一个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用。
2.运行时常量池是包含在非堆里,也就方法区。
1.程序计数器(线程私有)
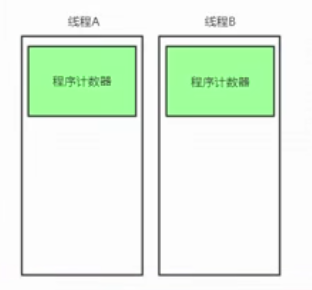
指向当前线程正在执行的字节码指令的地址 行号
既然当前线程正在执行,那为什么还要找个地方还要记录一下?是多余操作?
线程在cpu上执行,cpu在执行时是用时间片,时间片是抢占式的。线程是可以被挂起的,
当前的指令不一定就一定是一次性运行完的,所以需要找个地方把指令存起来。
每个线程都有一个自己的程序计数器。
2.虚拟机栈(线程私有)
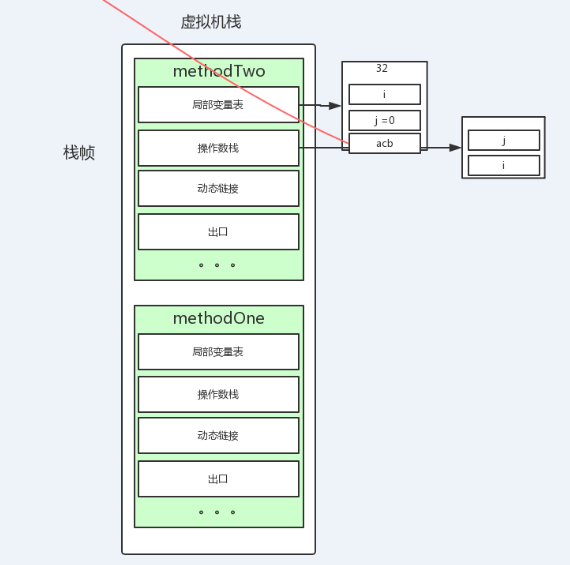
存储当前线程运行方法所需要的数据、指令、返回地址。
注意是方法,线程私有,当一个方法运行的时候,就会压到虚拟机栈。
栈帧:
方法运行时的基础数据结构,每个方法运行时都会创建一个栈帧。通俗的个人理解,
可以认为栈帧就是栈里的一个元素,当前栈帧就是顶部的要出栈的元素,这个元素是一个数据
结构,存储局部变量表,操作数栈,动态链接,出口等信息。
1.一个方法里是不是只压入一个栈?
不一定,如果方法里又调用方法,那么压入多个栈。
2.一个栈帧里面存储很多东西,重点关注如下
1.局部变量表
private Object obj = new Object();
public void print()
{
int a = 10;
int sum = a + 10;
Object object = obj;
return;
//todo
}
局部变量存的就是,局部变量,编译期可知。包括基本数据类型和对象引用,
例如:int a = 10 ,Object object = obj;
long 和 double类型数据占用2个局部变量空间(Slot),其余的数据类型只占用1个。
局部变量表所需内存空间在编译期间完成分配,当进入一个方法时,大小已经确定,不会在方法运行期间改变。.
2.操作数栈
方法里,做一些算术是在操作数栈里进行的。例如上面的 int sum = a + 10;
可以对class进行反编译,然后查看指令验证。
3.动态链接
每个栈栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用。
运行时常量池翻译的不好,其实是字面量,里面存的不仅是常量。
运行时常量池用于存放编译期生成的各种字面量和符号引用。例如:类里面引用到了另一个类,那么就要记录。
/**
* 只是存了符合引用
*/
private static Student student;
public static void main(String[] args) {
//实际运行时指向真正的引用地址
student.getName();
student.getAge();
}
4.方法出口
方法执行完后,要出栈,出栈后去哪里。
3.本地方法栈(线程私有)
基本和虚拟机栈一致,只是本地方法栈为虚拟机使用到的Native()方法服务。
4.方法区(线程共享)
public class StaticInit
{
//常量
public static final int DEFAULT_AGE = 10;
public static final String NAME = "标z仔";
//静态变量
private static int k = 0;
//成员变量
private int a = 1;
}
1.方法区也有人叫它“永久代”。jdk1.8之前java内存模型有永久代概念,永久代在方法区。
2.在HotSpot JVM中,只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。在其他JVM上不存在永久代。
3.方法区用于存放类信息、常量、静态变量、JIT(动态编译)及时编译后的代码等数据。
4.运行时常量池属于方法区的一部分,jdk1.7的HotSpot把原本方法区的字符串常量池、静态变量等移出。
5.jdk1.8
1.jdk1.8完全废弃了永久代概念,改用本地内存中实现的元空间。
2.取消永久代,方法区存放于元空间(Metaspace)。
3.元空间仍然与堆不相连,但与堆共享物理内存,逻辑上可认为在堆中 ,但是实际上我们说的堆指的是用于存放java对象的那些空间。
4.元空间并不在虚拟机中,而是使用本地内存。
6.为什么jdk1.8要把方法区从JVM里移到直接内存?
1.永久代有-XX:MaxPermSize上限,容易遇到内存溢出。而元空间使用的是直接内存,
受本机可用内存的限制,只要没有触碰到进程可用的内存上限理论上就不会有问题。
2.直接内存,JVM将会在IO操作上具有更高的性能,因为它直接作用于本地系统的IO操作。
而非直接内存,也就是堆内存中的数据,如果要作IO操作,会先复制到直接内存,再利用本地IO处理。
运行时常量池,字符池常量池,class常量池比较
参考链接:
https://blog.csdn.net/qq_26222859/article/details/73135660
1.全局字符串池(string pool也有叫做string literal pool)
全局字符串池里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中(记住:string pool中存的是引用值而不是具体的实例对象,具体的实例对象是在堆中开辟的一块空间存放的。)。
在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等同被赋予了”驻留字符串”的身份。
这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。
2.class文件常量池(class constant pool)
我们都知道,class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。
字面量就是我们所说的常量概念,如文本字符串、被声明为final的常量值等。
符号引用是一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可(它与直接引用区分一下,直接引用一般是指向方法区的本地指针,相对偏移量或是一个能间接定位到目标的句柄)。
3.运行时常量池(runtime constant pool)
jvm在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。
而当类加载到内存中后,jvm就会将class常量池中的内容存放到运行时常量池中,由此可知,运行时常量池也是每个类都有一个。在上面我也说了,class常量池中存的是字面量和符号引用,也就是说他们存的并不是对象的实例,而是对象的符号引用值。
而经过解析(resolve)之后,也就是把符号引用替换为直接引用,解析的过程会去查询全局字符串池,也就是我们上面所说的StringTable,以保证运行时常量池所引用的字符串与全局字符串池中所引用的是一致的。
5.堆(线程共享)
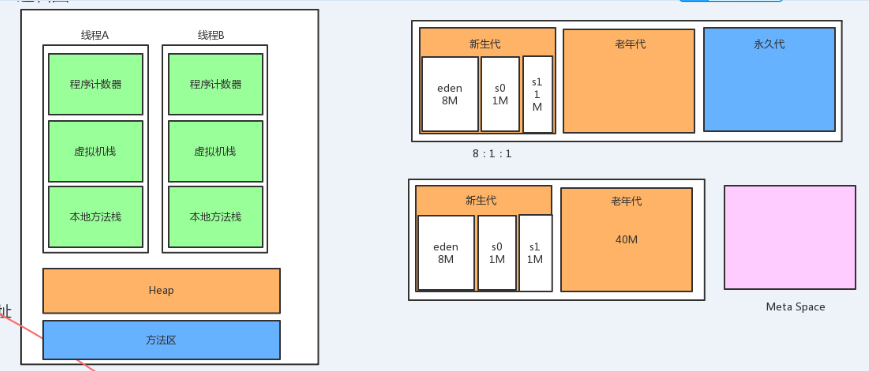
从右上图的堆内存结构图1.7和1.8对比可以看出:
1.jdk1.7有永久代,并且永久代是位于蓝色区域的方法区。
2.jdk1.8没有了永久代,取而代之的是元空间,同时元空间不属于方法区也不在堆,
但与堆共享物理内存,逻辑上可认为在堆中,元空间使用的是本地内存(Native Memory)
1.虚拟机启动时创建。
2.所有对象实例以及数组都要在堆上分配。但是随着JIT编译器的发展与逃逸分析技术 逐渐成熟,所有对象都分配在堆上分配也渐渐变得不是那么那么“绝对”了。
Java对象实例和数组元素都是在堆上分配内存的吗?
不一定,满足特定条件时,它们可以在(虚拟机)栈上分配内存
参考链接:
https://blog.csdn.net/mrchaochao/article/details/106668122
3.垃圾收集采用分代,所以细分可以新生代,老年代,永久代(1.8为元空间)。
4.物理上可以不连续,逻辑上连续即可。
对象的创建
对象所需的大小,在类加载完就可以完全确定。
1.内存分配
1.指针碰撞
如果java堆中的内存空间绝对规则,用过的内存都放在一边,空闲内存都放在另一边,中间放一个指针作为分界标识,
那么分配内存就是不停的移动指针而已,这个就是指针碰撞。
2.空闲列表
如果java堆中的内存空间不规则,可用与不可用相互交错,那么必须维护一个列表,记录哪些内存是可用的,分配对象是从列表里找出足够大
的内存分配,同时更新列表,这就是空闲列表。
2.线程安全问题
对象创建频繁,堆是所有线程共享区域,分配内存时存在并发问题, 解决方法:
1.加锁进行同步处理
2.TLAB线程本地分配缓存(常称栈上分配)
3.java内存模型和jvm内存模型
1.java内存模型是指规范了JVM如何提供按需禁用缓存和编译优化的方法。
具体来说,这些方法包括 volatile、synchronized 和 final 三个关键字,以及六项 Happens-Before 规则。
2.jvm内存模型又或称jvM内存结构,一般指咱们上面讲的那些运行时数据区域。
对象的内存布局

可以分为3块区域:对象头,实例数据,对齐填充
1.对象头
对象头存储是与对象自生定义的数据无关的额外信息:
.对象自身的运行时数据,如哈希码、GC分代年龄、锁状态标志、线程持有的锁...
.类型指针,虚拟机通过指针来确定这个对象是哪个类的实例。
2.实例数据
对象真正存储的有效数据,也就是我们写代码中定义的各种字段,父类和子类定义都要记录。
3.对齐填充
HotSpot VM 的要求对象起始地址必须是8字节的整数倍,当实例数据部分没有对齐,
就需要对齐填充补全,没有特别意义,不一定存在。
对象的访问
java程序需要通过栈上的reference数据来操作堆上的具体对象。
两种主流:
.使用句柄
.直接指针
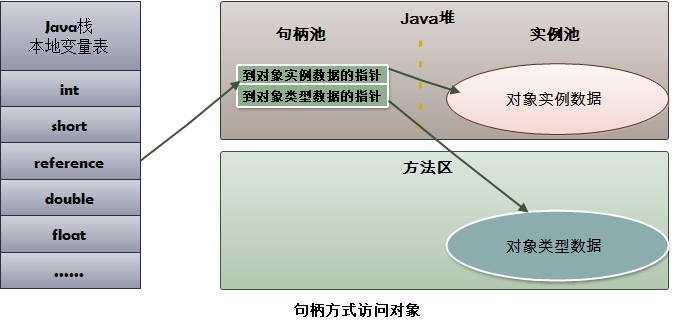
使用句柄,java堆中划分出一块内存来作为句柄池,reference中存储的是稳定的句柄地址,对象被垃圾回收,只会改变句柄中的实例数据指针,
而reference本身不用修改。
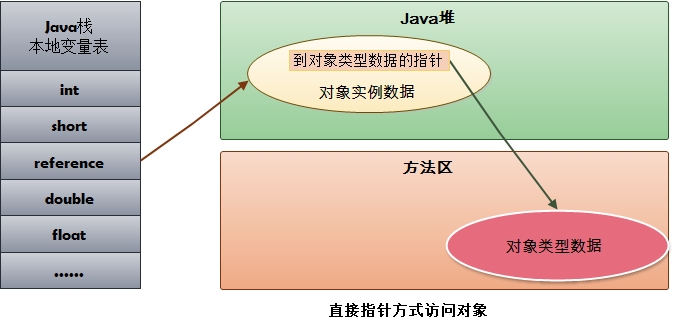
使用直接指针访问,java堆对象布局需要考虑如何放置访问类型数据的相关信息。
速度更快,节省一次指针定位的开销。HotSpot采用的是指针访问。
另外需要注意的是,类信息是在方法区存储,对象类型数据例如当前对象是int类型、数组类型、string类型都是在类信息里定义的,所以对象类型数据是存储在方法区的。
什么样的对象需要被垃圾回收?
1.引用计数法
给对象添加一个引用计数器,当有对象引用它,计数就加1。引用失效,计数就减1。
缺点:很难解决对象之前相互引用的问题。
2.可达性分析法
1.简介
从“GC Roots”根节点,往下搜索,所走过的路径为引用链,当一个对象到 GC Roots 没有任何引用链,
就说明这个对象不可达,可以进行回收。
2.什么可以成为GCRoots?
.虚拟机栈中本地变量表引用的对象
.方法区中:
类静态变量引用的对象
常量引用的对象
.本地方法栈中JNI引用的对象
3.为什么这些可以成为GCRoots?
1.虚拟机栈中本地变量表引用的对象
虚拟机栈中本地变量表引用的对象在线程中是保持活跃性,不能一下子回收,
private Object obj = new Object();
public void print()
{
int a = 10;
int sum = a + 10;
Object object = obj;
return;
//todo
}
通俗的讲,调用方法时你把方法内引用的对象给回收了,那我还怎么执行方法。
例如上面的objectd对象,我运行方法时发行被回收了,那我就没法运行了。
2.方法区中
类静态变量引用的对象被他们的类持有,类一般不回轻易回收,类本身可以被垃圾收集,这将删除所有引用的静态变量。所以类静态变量引用的对象是GC根。
常量引用个人理解,常量是一直要使用的不能够轻易回收,所以也能成为GC根。
方法区1.7以前也有成为永久代,所以不进行垃圾回收。
3.本地方法栈中JNI引用的对象
JNI引用是本机代码在JNI调用中创建的Java对象。这样创建的对象会被特殊处理,因为JVM不知道本机代码是否引用了它。这些对象表示一种非常特殊的GC根形式。
4.我们也可以写测试用例验证。
4.不可达是否立即回收?
不一定,真正宣告死亡至少要两次标记过程,
我们可以覆写finalize()方法,重新给对象挂上引用,使其逃脱被回收的命运。
垃圾回收
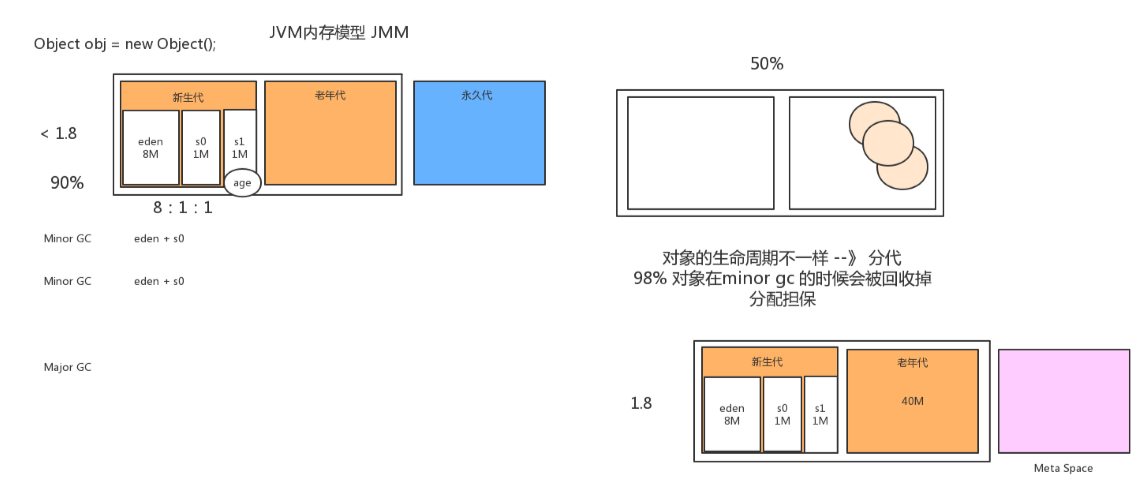
1.为什么进行分代?
对象的生命周期不一样。
2.认识几个常用jvm参数
官方网站地址:
https://www.oracle.com/java/technologies/javase/vmoptions-jsp.html
-X 和 -XX 开头说明:
Options that begin with -X are non-standard (not guaranteed to be supported on all VM implementations), and are subject to change without notice in subsequent releases of the JDK.
Options that are specified with -XX are not stable and are subject to change without notice.
堆的大小设置:
-Xms20M starting 起始堆大小
-Xmx max 最大的大小
-Xmn new 堆的新生代大小
对象分配eden
-XX:SurvivorRatio=8
8:1:1
3.为什么新生代默认比例是8:1:1?
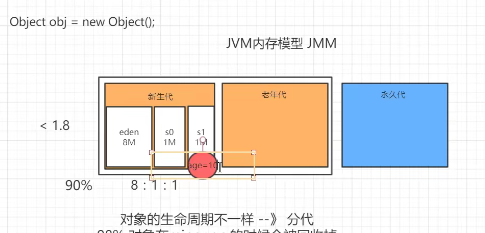
垃圾回收进行分代操作是希望大部分的对象在minor gc 时候就可以被回收掉,也就是在新生代的时候就希望被回收。而不是进入其它区域
触发major gc 或者 full gc。
新生代采用的是复制算法。
1.经过统计,每次gc会有90%的对象被回收,所以要预留空间去保存剩下的10%。
eden区设置的大,survivor区设置的小。
2.设置两个Survivor区最大的好处就是解决了碎片化。
假设刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,
下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,
很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。内存产生碎片化后,堆中没有足够大的连续内存空间,会导致内存不可用,浪费内存。
设置两个Survivor,第一次eden满了,触发一次minor gc,存活的对象往s1移动。第二次eden满了,垃圾回收的是整个年轻代(包括s1和s2,只是现在s2是空的)。
此时存活的对象,全部往s2移动,清空s1。下一次再gc, 存活的对象全部往s1移动,如此反复。
解决了空间内存碎片化,同时,对象可以较长的时间呆在新生代,直到达到对象的年龄设置的阈值才往老年代移动。
所以新生代会有10%的内存空间被浪费。
另外,如果存活对象在survivor区放不下,将触发分配担保机制,进入老年代。
https://blog.csdn.net/antony9118/article/details/51425581
4.垃圾收集算法
标记-清除,复制,标记-整理
目前商业虚拟机大多采用分代收集算法,新生代采用复制,老年代采用标记清理或标记整理。
5.什么是OopMap?
1.OopMap 用于枚举 GC Roots。
2.可达性分析,需要先找到GC Roots根节点,根节点往往存在于栈帧中的本地变量表或者全局性的引用(常量或类静态属性),
引用非常多,不可能每次都逐一检查,例如:如果需要知道栈帧中的本地变量表里有哪些引用,不可能逐一扫描方法区。
3.OopMap是一个数据结构,用于记录java栈上的对象引用,它的主要目的是在Java栈上查找GC根,
并在对象在堆中移动时更新引用,减少查找GC根节点时间。
这两篇文章可以学习下:
什么是oopMap?:
https://stackoverflow.com/questions/26029764/what-does-oop-maps-means-in-hotspot-vm-exactly.
R大:
https://www.iteye.com/blog/rednaxelafx-1044951
6.rememberedSet
主要是G1使用的一个辅助结构,解决跨代之前的引用,在G1时详细研究。
https://tech.meituan.com/2016/09/23/g1.html
https://docs.oracle.com/javase/9/gctuning/garbage-first-garbage-collector-tuning.htm#JSGCT-GUID-379B3888-FE24-4C3F-9E38-26434EB04F89
7.安全点Safe Point
OopMap栈上特定的位置记录信息,这些位置称为安全点。
即程序执行时并非在所有的地方都能停顿下来GC,只有在到达安全点时才能暂停。
.抢先式中断
.主动式中断
8.安全区域Safe Region
Safe Point 机制只能解决运行的线程如何进入GC问题,无法解决线程不执行的情况(睡眠,阻塞…)。
Safe Region 安全区域用于解决上诉问题。线程执行到安全区域代码,会标识自己已经进入安全区域,当发生GC时,就不用管标识自己为安全区域状态的线程。
再线程要离开安全区域,不是立即可以离开,需要先检查是否完成了GC过程,如果完成了,那么线程可以离开。否则,必须要等到接收到可以离开的信号为止。
9.垃圾收集器
我们项目用G1,所以会比较详细的研究下G1,我们单独开一个专门的页面讲G1。