AC算法过滤游戏里敏感词汇实战
目录
屏蔽字校验–AC算法
算法理解参考文章:
http://www.hyuuhit.com/2018/06/12/Aho%E2%80%93Corasick-Algorithm/
http://www.hankcs.com/program/algorithm/aho-corasick-double-array-trie.html
图片来自上面链接:

1.处理敏感词汇表数据
@Override
public void init(List<IDictBase> l)
{
super.init(l);
HashSet<String> chatSet = new HashSet<>();
HashSet<String> nameSet = new HashSet<>();
TIntObjectIterator<DictSensitiveWord> iterator = map.iterator();
while(iterator.hasNext())
{
iterator.advance();
DictSensitiveWordData config = (DictSensitiveWordData) iterator.value();
String word = config.getWord();
if(word.contains("&"))
{
continue;
}
if(config.isChatCheck)
{
chatSet.add(word);
}
if(config.isNameCheck)
{
nameSet.add(word);
}
}
String[] chatArr = new String[chatSet.size()];
chatSet.toArray(chatArr);
String[] nameArr = new String[nameSet.size()];
nameSet.toArray(nameArr);
ChatUtils.load(chatArr, nameArr);
}
分析:分别将聊天屏蔽字和命名屏蔽字字符串转为字符串数组,调用load()方法初始化AC算法敏感词数据结构
2.AC算法初始化构造的串(敏感词汇,过滤符号)
这里我们自己举例验证
/**
* @author lizhibiao
* @date 2019/8/1 15:57
*/
public class DFATest
{
public static final char SUBSTITUTE_CHAR = '*';
private static final char[] IGNORE_CHARS = { ' ', ' ', '*', '-', '_', '+', '/', '.', '(', ')', '&', '%', '$', '#',
'@', '!' };
private static KeyWordsACFilter util = null;
public static void main(String[] args)
{
init();
boolean result = util.contain("shis");
System.out.println(result);
}
private static void init()
{
String[] keys = {"he", "she", "his", "hers"};
util = new KeyWordsACFilter(IGNORE_CHARS, SUBSTITUTE_CHAR);
util.initialize(keys);
}
}
分析:初始化构造”he”, “she”, “his”, “hers”敏感词汇goto表和failure表
3.构造goto表
/**
* 构造goto表
* @param keyWords
* @return
*/
public boolean initialize(String[] keyWords) {
clear();
for (int s = 0; s < keyWords.length; s++) {
String _keyword = keyWords[s];
if (_keyword == null || (_keyword = _keyword.trim()).length() == 0) {
continue;
}
char[] patternTextArray = _keyword.toCharArray();
DFANode currentDFANode = dfaEntrance;
for (int i = 0; i < patternTextArray.length; i++) {
final char _c = patternTextArray[i];
// 逐点加入DFA
final Character _lc = toLowerCaseWithoutConfict(_c);
DFANode _next = currentDFANode.dfaTransition.get(_lc);
if (_next == null) {
//如果为空就往当前节点的map里put操作
_next = new DFANode();
currentDFANode.dfaTransition.put(_lc, _next);
}
currentDFANode = _next;
}
//尾节点设置为终止状态
if (currentDFANode != dfaEntrance) {
currentDFANode.isTerminal = true;
}
}
//构造失效节点
buildFailNode();
return true;
}
分析:构造goto表比较简单不细分析,注意借鉴了DFA算法的终止状态,因此节点里加入终止状态。
4.构造failure表

/**
* 构造失效节点: 一个节点的失效节点所代表的字符串是该节点所表示它的字符串的最大 部分前缀
*/
private final void buildFailNode() {
// 以下构造失效节点
List<DFANode> queues = new ArrayList<DFANode>();
dfaEntrance.failNode = dfaEntrance;
//状态0是根节点,failure跳转为其自身。深度为1的状态节点failure跳转均为根节点。
for (Iterator<DFANode> it = dfaEntrance.dfaTransition.values().iterator(); it.hasNext(); ) {
DFANode node = it.next();
node.level = 1;
queues.add(node);
node.failNode = dfaEntrance;// 失效节点指向状态机初始状态
}
DFANode curNode = null;
DFANode failNode = null;
while (!queues.isEmpty()) {
// 该节点的失效节点已计算
curNode = queues.remove(0);
//当前节点的失效节点
failNode = curNode.failNode;
//迭代取的是当前节点的下一节点,所以failNode和curNode就是父节点
for (Iterator<Map.Entry<Character, DFANode>> it = curNode.dfaTransition.entrySet().iterator(); it
.hasNext(); ) {
Map.Entry<Character, DFANode> nextTrans = it.next();
Character nextKey = nextTrans.getKey();
DFANode nextNode = nextTrans.getValue();
// 如果父节点的失效节点中没有相同的出边并且父节点不是根节点,那么失效节点就是父节点的失效节点
//例如再构建一个串skt,k的失效节点就是父节点的失效节点根节点,然后t的失效节点就是k的失效节点也是根节点
while (failNode != dfaEntrance && !failNode.dfaTransition.containsKey(nextKey)) {
failNode = failNode.failNode;
}
//如果父节点的失效节点中有相同的出边,那么当前节点的失效节点就是父节点的下一节点
nextNode.failNode = failNode.dfaTransition.get(nextKey);
if (nextNode.failNode == null) {
//如果父节点的失效节点中没有相同的出边,那么失效节点直接指向根节点
nextNode.failNode = dfaEntrance;
}
//下一节点的节点层数加1
nextNode.level = curNode.level + 1;
queues.add(nextNode);// 计算下一层
}
}
}
分析:failure表构造,我们以上面图片来细分析下代码
1.状态0是根节点,failure跳转为其自身。深度为1的状态节点failure跳转均为根节点。
for (Iterator<DFANode> it = dfaEntrance.dfaTransition.values().iterator(); it.hasNext(); )
{
DFANode node = it.next();
node.level = 1;
queues.add(node);
node.failNode = dfaEntrance;// 失效节点指向状态机初始状态
}
迭代的是深度为1的所有节点,将深度为1的全部节点的失效节点指向根节点,然后加入数组。
2.往下看while循环里操作
DFANode curNode = null;
DFANode failNode = null;
while (!queues.isEmpty()) {
// 该节点的失效节点已计算
curNode = queues.remove(0);
//当前节点的失效节点
failNode = curNode.failNode;
//迭代取的是当前节点的下一节点,所以failNode和curNode就是父节点
for (Iterator<Map.Entry<Character, DFANode>> it = curNode.dfaTransition.entrySet().iterator(); it
.hasNext(); ) {
这里当前节点curNode,失效节点是已经计算过了,然后迭代取的是当前节点的下一节点,所以failNode和curNode就是父节点
// 如果父节点的失效节点中没有相同的出边并且父节点不是根节点,那么失效节点就是父节点的失效节点
// 例如再构建一个串skt,k的失效节点就是父节点的失效节点根节点,然后t的失效节点就是k的失效节点也是根节点
while (failNode != dfaEntrance && !failNode.dfaTransition.containsKey(nextKey)) {
failNode = failNode.failNode;
}
我们刚开始初始化构造敏感词是不包含skt,假设我们再构造一个skt串,那么k的失效节点就是父节点的失效节点根节点,然后t的失效节点就是k的失效节点也是根节点
//如果父节点的失效节点中有相同的出边,那么当前节点的失效节点就是父节点的下一节点
nextNode.failNode = failNode.dfaTransition.get(nextKey);
if (nextNode.failNode == null) {
//如果父节点的失效节点中没有相同的出边,那么失效节点直接指向根节点
nextNode.failNode = dfaEntrance;
}
所以,状态4指向状态1,状态5指向状态2
//下一节点的节点层数加1
nextNode.level = curNode.level + 1;
// 计算下一层
queues.add(nextNode);
下一节点的节点层数加1,然后加入数组,继续计算下一层的失效节点
3.这里我们以状态3、4、5失效节点构造为例,一看就能明白原来(可以结合断点一步一步看)
首先状态3深度为1,那么其失效节点就是根节点。
第一次:
1.CurNode = <h<e,0» 父节点(注意:这里的0只是代表下一节点长度为0简写方便)
2.failNode = 根节点数据结构
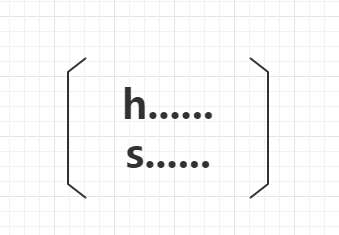
3.nextKey = h
4.nextNode = <e, 0>
5.nextNode.failNode = failNode.dfaTransition.get(nextKey);
根节点包含h边,所以nextNode的失效节点就是根节点的下一节点,也就是状态1。
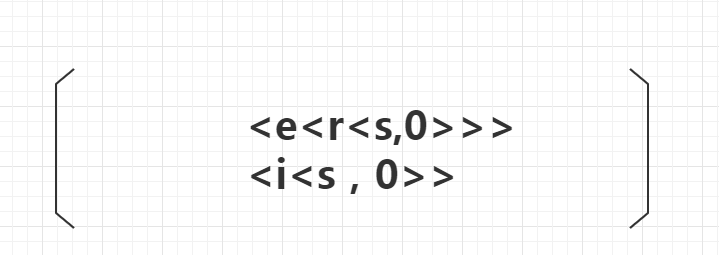
所以状态4的失效节点指向状态1。
6.下一节点的节点层数加1,然后加入数组,继续计算下一层的失效节点
<e,0>节点加入数组,下次继续计算
第二次:
1.CurNode = <e, 0>
2.failNode 也就是状态1
3.nextKey = e
4.nextNode长度为0
5.nextNode.failNode = failNode.dfaTransition.get(nextKey);
因为父节点有相同出边,所以失效节点为下一节点<r<s,0»,即状态2。
因此,状态5的失效节点指向状态2。
4.根据构建的goto和failure表结构判断是否存在敏感字
public boolean contain(final String inputMsg)
{
char[] input = inputMsg.toCharArray();
DFANode currentDFANode = dfaEntrance;
DFANode _next = null;
for (int i = 0; i < input.length; i++) {
final Character _lc = this.toLowerCaseWithoutConfict(input[i]);
//这里扩展isIgnore添加一些忽略字符
if (!isIgnore(_lc)) {
_next = currentDFANode.dfaTransition.get(_lc);
//例如:我的字符是shers,那么先匹配到she,然后跳转失效节点
//如果下一节点等于null并且当前节点不是根节点,说明已经到末尾了,例如she的e字符是末尾字符
//那么当前节点e就要跳转到失效节点2然后继续重复判断
while (_next == null && currentDFANode != dfaEntrance) {
//那么当前节点直接跳转到失效节点
currentDFANode = currentDFANode.failNode;
//并且继续判断失效节点的下一节点
_next = currentDFANode.dfaTransition.get(_lc);
}
}
if (_next != null) {
// 找到状态转移,可继续
currentDFANode = _next;
}
// 看看当前状态可退出否
if (currentDFANode.isTerminal) {
// 可退出,记录,可以替换到这里
return true;
}
}
return false;
}
分析:检验是否包含敏感词,如果goto表中当前状态对于字符a没有合法跳转,则根据failure表转移状态。 当前状态可退出,说明匹配上。
5.我们可以根据自己的实际需求扩展
工具类代码:
项目未上线,暂时不能公开。